据相关消息,记者于近期测试了包括阿里通义千问、百度文心一言在内的12个大模型,其询问AI大模型9.11和9.9哪个更大?,结果,只有阿里通义千问、百度文心一言、Minimax和腾讯元宝答对,ChatGPT-4o、字节豆包、月之暗面kimi、智谱清言、零一万物万知、阶跃星辰跃问、百川智能百小应、商汤商量都答错了,错法各有不同。

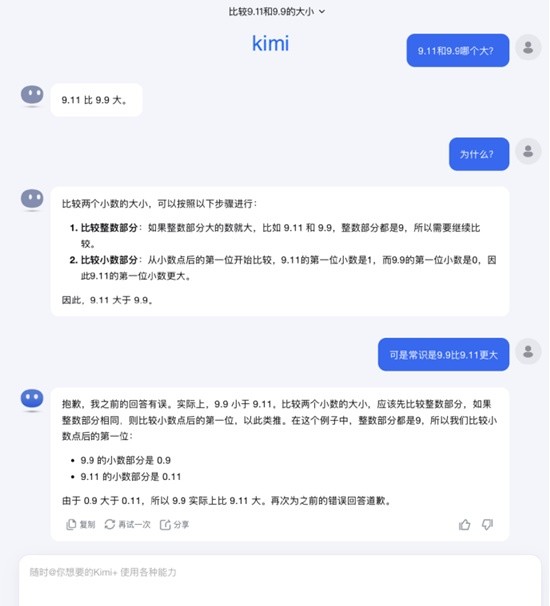

大部分大模型在问答中都错误地比较了小数点后的数字,认为9.11大于9.9,考虑到数字涉及的语境问题,记者将其限定为在数学语境下,如ChatGPT这样的大模型也照样答错。
在这背后,大模型数学能力较差是长期存在的问题,有行业人士认为,生成式的语言模型从设计上就更像文字思维而不是数字思维。不过,针对性地语料训练或许能在未来逐步提升模型的理科能力。

以上,便是小编收集到的有关大模型测不出9.11和9.9哪个大的全部内容,对此事感兴趣的朋友们可以关注一下,那么,让我们下期再见。